ProtectYourVoice: Detacting AI Generated Voice using Deep Learning
Table of Contents
Disclaimer: This project, developed by Jiazhou Liang, Joe Liu, Tunghoi Yeung, and Yuechen Shi, is provided for non-commercial use. You are welcome to utilize the code for non-commercial purposes. Please note that the datasets incorporated in this project retain their original copyright held by their respective authors, as cited below.
Introduction
AI-generated (conversion) voices/speech have become increasingly popular, but they also present challenges in fraud prevention, such as impersonating someone to make fraudulent calls.
The problem that our deep fake voice detector aims to solve is the proliferation of audio-based misinformation and fraudulent activities facilitated by the advancement of deep learning techniques. With the rise of deep fake technology, individuals can manipulate audio recordings to create convincing fake voices that can be used for various malicious purposes, such as spreading false information, impersonating others, or committing fraud.
We think this project is crucial for safeguarding the authenticity and reliability of audio content, thereby preserving trust in communication channels and preventing harm caused by misinformation or malicious activities.
Methodology
To address this issue, we wish to implement a deep learning model to detect whether a piece of audio comes from a real person or is AI-generated, specifically focusing on the fake voices generated by deep learning models, e.g. Audio Deepfake (AD).
Current appoarch
Current approaches, such as the work from Bird et al., rely on classical statistical learning models like XGBoost and SVM for this task. Also, most approaches have various limitations, such as requiring special data processing to perform well, not resisting noises, and being limited to English speeches. Also, Bird et al. approach the dataset size as related to small. We aim to explore the performance of deep learning models in this problem domain, with a focus on resolving some limitations in the current approaches.
Pipline
The proposed approach involves four steps:
- Converting the length of audio into a fixed length (30 seconds in this project).
- Converting the raw audio (signal) into a spectrogram, which is a visual representation of its Fourier transformation.
- Applying a CNN model, treating the spectrogram as an RGB image, to find the unique features within it.
- Performing binary classification on these features to detect whether the audio is AI-generated or from a real human.
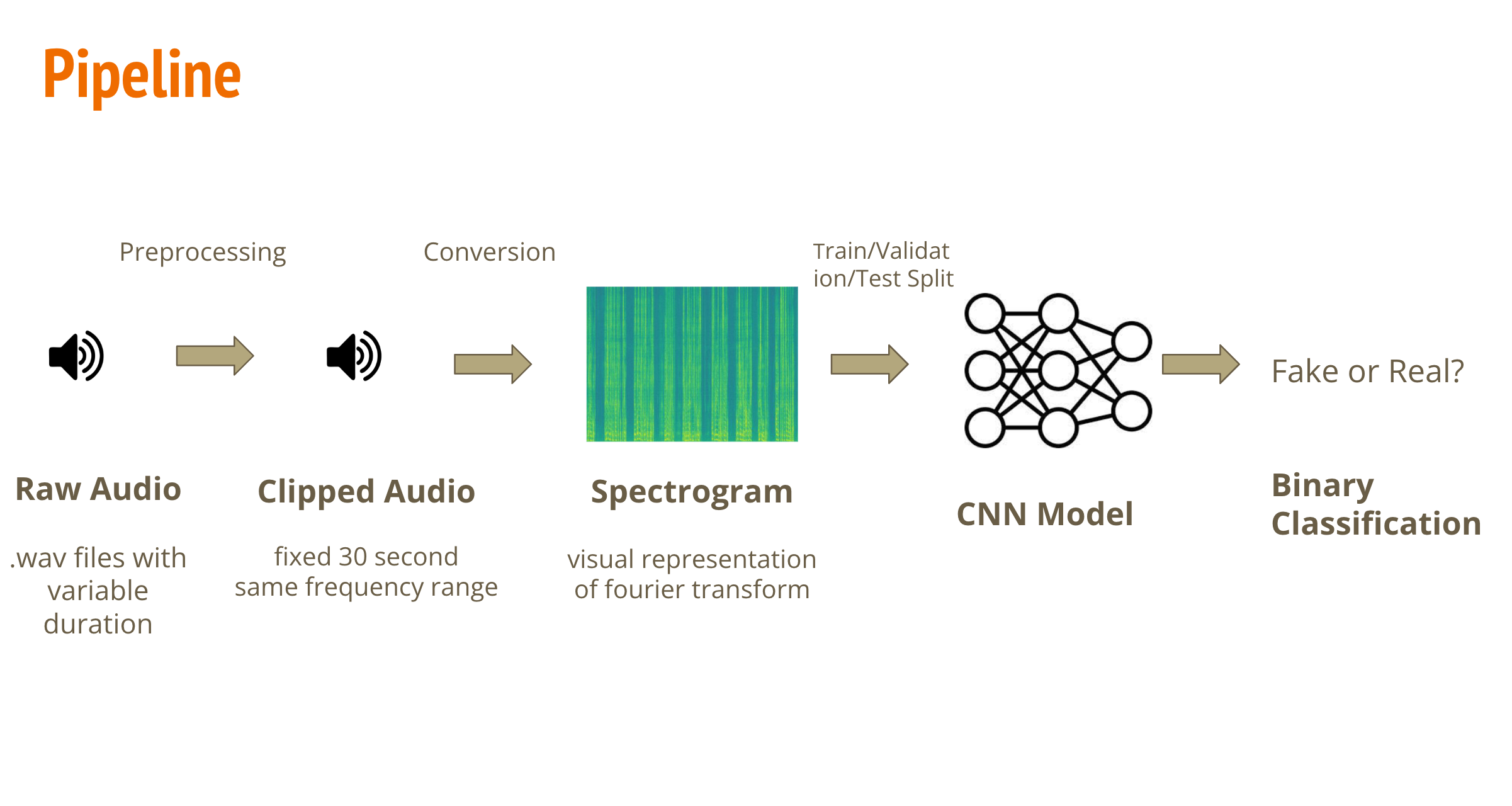
We will demonstrate the training process of this proposed approach, including dataset extraction, model selection, and performance evluation.
Import packages
# install missing packages in colab
# for audio segment
!pip install pydub
# for dataset download
!pip install -q kaggle
#import required packages
from pydub import AudioSegment
from scipy.io import wavfile
import soundfile as sf
from tqdm import tqdm
import os
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
import matplotlib.image as mpimg
import os
import shutil
location = ''
# for better visualization
import warnings
warnings.filterwarnings("ignore")
# mount google drive folder
from google.colab import drive
drive.mount('/content/drive')
location = '/content/drive/MyDrive/shared-project-folder/'
Dataset
It is worth noting that there are various AD datasets available.
- This project will use the “DEEP-VOICE: DeepFake Voice Recognition” dataset from Bird et al., as mentioned in the proposal, which was published on Kaggle. It is a smaller dataset that contains 64 raw audio files converted from the speeches of 8 public figures into other people’s voices using Retrieval-based Voice Conversion.
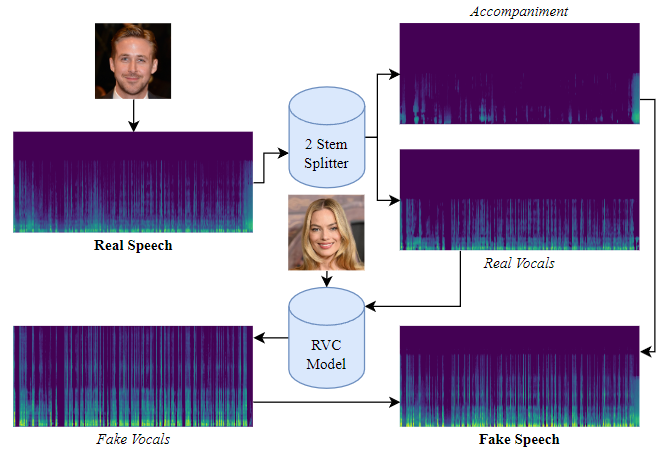
(Here is the illustration of how fake data is generated, according to Bird & Lotfi, 2023.) The average length of each sample is 600 seconds. To increase the sample size and reduce the length of each sample, we cut each sample into groups of 30-second clips.
- While the Kaggle data contains audios coming from or mimicking a small number of celebrities, we would like our model to perform well on a wide variety of voices. ASVspoof 2019 was a database used for the Third Automatic Speaker Verification Spoofing and Countermeasures Challenge. We looked at a partition of ASVspoof 2019(within the “LA” folder in the original dataset) where the fake audios were generated by text-to-speech or voice conversion systems, from speech data captured from 107 speakers (46 males, 61 females) reading a list of text corpora. Here is the link to the original dataset: (https://datashare.ed.ac.uk/handle/10283/3336)
However, in contrast to the ‘Deep-Voice’ dataset, most of the audios are around 2 to 6 seconds long. We concatenate all the audios that have the same label (real or fake) and correspond to the same speaker together. In this way, the concatenated audios will have a closer length to the ones from Kaggle, and then we can split them into 30-second intervals in the same way.
Let us discuss the preprocessing of each dataset separately.
“DEEP-VOICE: DeepFake Voice Recognition” from kaggle
Download and process dataset
We need to download both dataset at the very first time, processed it, stored it in google drive for future usage.
from google.colab import files
#upload your kaggle api json (https://www.kaggle.com/docs/api#interacting-with-datasets)
files.upload()
!ls -lha kaggle.json
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 /root/.kaggle/kaggle.json
!pwd
!kaggle datasets download -d birdy654/deep-voice-deepfake-voice-recognition
unzip and processing dataset
!unzip /content/deep-voice-deepfake-voice-recognition.zip
fake_files = os.listdir('/content/KAGGLE/AUDIO/FAKE')
real_files = os.listdir('/content/KAGGLE/AUDIO/REAL')
print(f'Real voice samples: {len(real_files)}')
print(f'Fake voice samples: {len(fake_files)}')
Real voice samples: 8
Fake voice samples: 56
It worth noting that this is an imbalanced dataset (much more fake sample than real samples), we need to take this issue into account when eveluating the model.
audio = AudioSegment.from_wav('/content/KAGGLE/AUDIO/REAL/' + real_files[4])
length_audio = len(audio)
print(f'a random sample from real voice has {length_audio} millisecond')
a random sample from real voice has 600176 millisecond
We need to first convert the audio from wave into spetrogram before feed it into deep learning model. For ‘Deep-Voice’ dataset, as we metioned above, since each voice samples is relatively long (600 second) and overall sample size is small (64 samples), we want to utilizing data augmentation techniques to cut each sample into smaller segement to reduces the pixels per samples and increasing the sample size.
## some helper functions
def remove_all_files(folder_path):
"""
Remove all old files in a folder and its subfolders.
"""
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
if os.path.isfile(file_path):
os.remove(file_path)
else:
remove_all_files(file_path)
def split_audio(file_path, segment_length=30000, random_length = None) -> list:
"""
Split the audio file into segments of given length (in milliseconds).
Returns a list of audio segments.
"""
audio = AudioSegment.from_wav(file_path)
length_audio = len(audio)
segments = []
# Random Length: None or [lower, upper]
# Generating a random segement length from given lower to upper range
if random_length is not None:
current_length = 0
while current_length < len(audio):
segment_length = np.random.randint(random_length[0],random_length[1],1)
if current_length + segment_length >= len(audio):
segment = audio[current_length:]
else:
segment = audio[current_length:current_length + segment_length]
current_length += segment_length
segments.append(segment)
# fix length: cut samples based on given fixed segment_length
else:
for i in range(0, length_audio, segment_length):
segment = audio[i:i + segment_length]
segments.append(segment)
return segments
Our audio-cutting function allows both fixed-length cutting (30 seconds by default) and random-length cutting (within a specified range) to accommodate real-world examples that different voice tends to have different length (leaving design space for possible future expansion). For now, we will cut each voice sample into fixed 30-second intervals and convert each interval into a spectrogram.
Converting real voice
# obtain all files from fake and real folders
fake_files = os.listdir('/content/KAGGLE/AUDIO/FAKE')
real_files = os.listdir('/content/KAGGLE/AUDIO/REAL')
os.makedirs('real',exist_ok=True)
#remove old files if exists
remove_all_files('real')
#iterating through all audio in the real files
for wav_file in real_files:
print('Processing: ', wav_file)
output_folder = 'real'
#split to 30 seconds segments
segments = split_audio('/content/KAGGLE/AUDIO/REAL/'+wav_file)
for i, segment in enumerate(segments):
segment = segment.set_channels(1)
samples = np.array(segment.get_array_of_samples())
#converting each segments into spectrograms
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate, noverlap=512)
plt.axis('off')
#save the spectrograms for future usage
plt.savefig(os.path.join('real', wav_file[:-5]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
Processing: linus-original.wav
Processing: biden-original.wav
Processing: ryan-original.wav
Processing: margot-original.wav
Processing: taylor-original.wav
Processing: musk-original.wav
Processing: obama-original.wav
Processing: trump-original.wav
Convert fake voice
Using the same process as the real samples, we can convert all AI generated samples into the 30 seconds spectrogram
os.makedirs('fake',exist_ok=True)
#remove old files if exists
#remove_all_files('fake')
for wav_file in fake_files[46:]:
print('Processing: ', wav_file)
segments = split_audio('/content/KAGGLE/AUDIO/FAKE/'+wav_file)
for i, segment in enumerate(segments):
segment = segment.set_channels(1)
samples = np.array(segment.get_array_of_samples())
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate, NFFT=1024, noverlap=512)
plt.axis('off')
plt.savefig(os.path.join('fake', wav_file[:-5]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
Processing: musk-to-taylor.wav
Processing: margot-to-taylor.wav
Processing: margot-to-ryan.wav
Processing: linus-to-musk.wav
Processing: ryan-to-trump.wav
Processing: taylor-to-biden.wav
Processing: trump-to-linus.wav
Processing: taylor-to-margot.wav
Processing: margot-to-obama.wav
Processing: biden-to-margot.wav
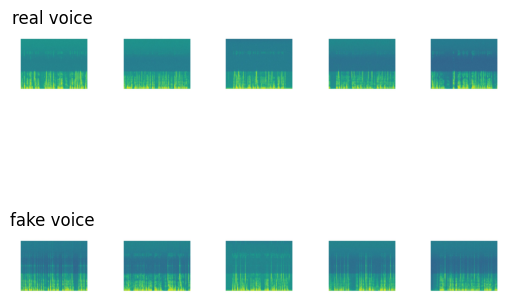
Some examples
Lets see some examples of the real and fake voices in the spectrograms
#coverted segment
real_spectro = os.listdir('/content/drive/MyDrive/shared-project-folder/kaggle/real')
fake_spectro = os.listdir('/content/drive/MyDrive/shared-project-folder/kaggle/fake')
# Display random five real and fake voice spectrogram
count = 0
fig, axs = plt.subplots(2,5)
for i in np.random.choice(range(len(real_spectro)),5):
image_path = real_spectro[i]
image = mpimg.imread(os.path.join('/content/drive/MyDrive/shared-project-folder/kaggle/real',image_path))
axs[0,count].imshow(image)
image_path = fake_spectro[i]
image = mpimg.imread(os.path.join('/content/drive/MyDrive/shared-project-folder/kaggle/fake',image_path))
axs[1,count].imshow(image)
axs[0,count].axis('off')
axs[1,count].axis('off')
if count == 0:
axs[0,count].set_title('real voice')
axs[1,count].set_title('fake voice')
count += 1
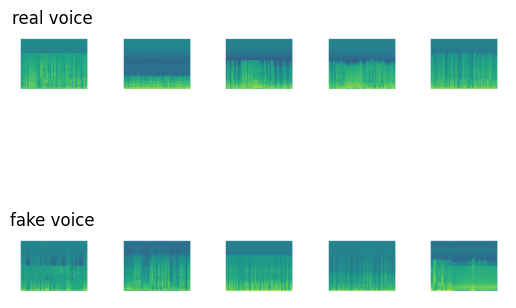
image.shape
(539, 542, 3)
The result spectrogram is represented as an RGB image with dimension 539 * 542. We will transformed it into a fix dimension for CNN model.
Train/Test splitting and regrouping samples into Pytorch ImageFolder structure
However, the spectrogram of real and fake voice segments are stored in two different folders. To utilize the convenient features in Torch’s ImageFolder, we have to split the dataset into train and test sets and convert them into the required format.
Moreover, we will spliting the dataset into train/test set in this steps, with 0.2 as the thersholds
from posix import remove
from sklearn.model_selection import train_test_split
from PIL import Image
# if the google drive is mounted, we can store the dataset into google drive for future usage
if os.path.exists('drive'):
location = '/content/drive/MyDrive/shared-project-folder/kaggle'
else:
# if not, stored it in runtime (required downloading processing data everytime)
location = ''
if not os.path.exists(os.path.join(location,'train')):
# Create the directory.
os.makedirs(os.path.join(location,'train'))
#real samples
os.makedirs(os.path.join(location,'train','1'))
#fake samples
os.makedirs(os.path.join(location,'train','0'))
# combine all spectrogram
all_spectro = real_spectro + fake_spectro
# create label 1: real 0:fake
all_spectro_label = [1 for i in range(len(real_spectro))] + [0 for i in range(len(fake_spectro))]
#split
X_train, X_test, y_train, y_test = train_test_split(all_spectro, all_spectro_label, test_size=0.2, random_state=42)
for i in range(len(X_train)):
y = y_train[i]
destination_path = os.path.join(location,'train',str(y), X_train[i])
with Image.open(['/content/drive/MyDrive/shared-project-folder/kaggle/fake/',
'/content/drive/MyDrive/shared-project-folder/kaggle/real/'][y] + X_train[i]) as img:
img.save(destination_path)
if not os.path.exists(os.path.join(location,'test')):
os.makedirs(os.path.join(location,'test'))
os.makedirs(os.path.join(location,'test','1'))
os.makedirs(os.path.join(location,'test','0'))
for i in range(len(y_test)):
y = y_test[i]
destination_path = os.path.join(location,'test',str(y), X_test[i])
with Image.open(['/content/drive/MyDrive/shared-project-folder/kaggle/fake/',
'/content/drive/MyDrive/shared-project-folder/kaggle/real/'][y] + X_test[i]) as img:
img.save(destination_path)
After cutting, converting into spectrogram, and re-ordering the file structure, we obtain a cleaned ‘Deep-Voice’ dataset that ready from model training. The cleaned dataset is stored in ‘kaggle’ folder of the shared google drive
ASVspoof 2019 from DataShare
Next, lets process the ASVspoof dataset, this dataset is much larger than the previous Kaggle dataset, so we need to download it directly into the colab and it will take sometimes
!wget https://datashare.ed.ac.uk/bitstream/handle/10283/3336/LA.zip
--2024-03-29 15:35:48-- https://datashare.ed.ac.uk/bitstream/handle/10283/3336/LA.zip
Resolving datashare.ed.ac.uk (datashare.ed.ac.uk)... 129.215.67.172
Connecting to datashare.ed.ac.uk (datashare.ed.ac.uk)|129.215.67.172|:443... connected.
HTTP request sent, awaiting response... 200 200
Length: 7640952520 (7.1G) [application/zip]
Saving to: ‘LA.zip’
LA.zip 100%[===================>] 7.12G 26.0MB/s in 5m 34s
2024-03-29 15:41:22 (21.8 MB/s) - ‘LA.zip’ saved [7640952520/7640952520]
!unzip LA.zip
Note: As the file paths in the following code cells indicated, we processed ASVspoof2019 LA locally. Processing on Google Colab would require large RAM and drive space, which have a high chance of crashing when using free colab account
Basic statistic of dataset
The ASVspoof dataset has a pre-defined train/validate/test split, we will not change its original split, so we retreives and process train/val/test data seperatly to ensure they are properly handle
training set
train_df = pd.read_csv(f'LA/ASVspoof2019_LA_cm_protocols/ASVspoof2019.LA.cm.train.trn.txt',
sep=" ", header=None)
train_df.columns =['speaker_id','filename','system_id','null','class_name']
train_df.drop(columns=['null'],inplace=True)
train_df['filepath'] = f'LA/ASVspoof2019_LA_train/flac/'+train_df.filename+'.flac'
# fake audios are labeled 0, real (bona fide) are labeled 1
train_df['target'] = (train_df.class_name=='bonafide').astype('int32')
real_speakers = train_df['speaker_id'][train_df['target']==1].unique()
print(f'{len(real_speakers)} real speakers')
fake_speakers = train_df['speaker_id'][train_df['target']==0].unique()
print(f'{len(fake_speakers)} fake speakers')
print(f'{sum([f_speaker in real_speakers for f_speaker in fake_speakers])} common speakers')
20 real speakers
20 fake speakers
20 common speakers
There are 20 real speakers, and 20 fake speakers, and 20 of them are within both real and fake speaker, which mean all of speakers’ voice contains in both real and fake samples.
validation set
valid_df = pd.read_csv(f'LA/ASVspoof2019_LA_cm_protocols/ASVspoof2019.LA.cm.dev.trl.txt',
sep=" ", header=None)
valid_df.columns =['speaker_id','filename','system_id','null','class_name']
valid_df.drop(columns=['null'],inplace=True)
valid_df['filepath'] = f'LA/ASVspoof2019_LA_dev/flac/'+valid_df.filename+'.flac'
# fake audios are labeled 0, real (bona fide) are labeled 1
valid_df['target'] = (valid_df.class_name=='bonafide').astype('int32')
real_speakers = valid_df['speaker_id'][valid_df['target']==1].unique()
print(f'{len(real_speakers)} real speakers')
fake_speakers = valid_df['speaker_id'][valid_df['target']==0].unique()
print(f'{len(fake_speakers)} fake speakers')
print(f'{sum([f_speaker in real_speakers for f_speaker in fake_speakers])} common speakers')
20 real speakers
10 fake speakers
10 common speakers
There are additional 10 speakers in the validation real dataset, which mean they do not have fake samples
test set
test_df = pd.read_csv(f'LA/ASVspoof2019_LA_cm_protocols/ASVspoof2019.LA.cm.eval.trl.txt',
sep=" ", header=None)
test_df.columns =['speaker_id','filename','system_id','null','class_name']
test_df.drop(columns=['null'],inplace=True)
test_df['filepath'] = f'LA/ASVspoof2019_LA_eval/flac/'+test_df.filename+'.flac'
# fake audios are labeled 0, real (bona fide) are labeled 1
test_df['target'] = (test_df.class_name=='bonafide').astype('int32')
real_speakers = test_df['speaker_id'][test_df['target']==1].unique()
print(f'{len(real_speakers)} real speakers')
fake_speakers = test_df['speaker_id'][test_df['target']==0].unique()
print(f'{len(fake_speakers)} fake speakers')
print(f'{sum([f_speaker in real_speakers for f_speaker in fake_speakers])} common speakers')
67 real speakers
48 fake speakers
48 common speakers
Similiar for the validation dataset, there are 19 speakers does not have fake samples. Let us examine the length of some samples
for i in range(10):
index = np.random.randint(0,train_df.shape[0], 1)
path = train_df['filepath'][index]
sound = AudioSegment.from_file(path.item(), format="flac")
print("Lengths (in seconds) of samples: ",sound.duration_seconds)
Lengths (in seconds) of samples: 3.74325
Lengths (in seconds) of samples: 4.227125
Lengths (in seconds) of samples: 4.0983125
Lengths (in seconds) of samples: 2.2131875
Lengths (in seconds) of samples: 4.6369375
Lengths (in seconds) of samples: 3.8778125
Lengths (in seconds) of samples: 3.84675
Lengths (in seconds) of samples: 2.6333125
Lengths (in seconds) of samples: 1.569875
Lengths (in seconds) of samples: 1.510125
Combining samples
We observed that the length of each sample is quite short. To accommodate real-world scenarios, we decided to combine the voices from the same speaker together (fake with fake, real with real) to create longer voice segments.
from os.path import exists
# load the csv that contains the speaker id of each audio, and concat the audio into a single audio
def concat_audio(ref, dataset):
speaker = ref['speaker_id'].unique()
for current_speaker in speaker[27:]:
print('Processing', current_speaker)
real = np.empty((0,), dtype=np.int16)
fake = np.empty((0,), dtype=np.int16)
# group by speaker
voice_from_speaker = ref[ref['speaker_id'] == current_speaker]
for i, row in voice_from_speaker.iterrows():
data,sample_rate = sf.read(row['filepath'])
#group by label
if row['target'] == 1:
real = np.append(real, data)
else:
fake = np.append(fake, data)
if real.shape[0] != 0:
print('Real Exist')
if dataset == 'train':
out_path = 'LA_concated/train/real'
elif dataset == 'validation':
out_path = 'LA_concated/validation/real'
else:
out_path = 'LA_concated/test/real'
os.makedirs(out_path, exist_ok=True)
#combine and save
sf.write(os.path.join(out_path,current_speaker+'.flac'), real, sample_rate)
if fake.shape[0] != 0:
print('Fake Exist')
if dataset == 'train':
out_path = 'LA_concated/train/fake'
elif dataset == 'validation':
out_path = 'LA_concated/validation/fake'
else:
out_path = 'LA_concated/test/fake'
os.makedirs(out_path, exist_ok=True)
sf.write(os.path.join(out_path,current_speaker+'.flac'), fake, sample_rate)
concatenate audio separately
concat_audio(train_df, 'train')
concat_audio(valid_df, 'validation')
concat_audio(test_df, 'test')
checking the length of concated voice segement in some samples:
files = os.listdir('LA_concated/train/real')
for i in range(5):
index = np.random.randint(0,len(files), 1)
path = files[index[0]]
if path[-5:] == '.flac':
sound = AudioSegment.from_file('LA_concated/train/real/' + path, format="flac")
print("Lengths (in seconds) of real samples: ",sound.duration_seconds)
sound = AudioSegment.from_file('LA_concated/train/fake/' + path, format="flac")
print("Lengths (in seconds) of fake samples: ",sound.duration_seconds)
Lengths (in seconds) of real samples: 438.0238125
Lengths (in seconds) of fake samples: 4188.132875
Lengths (in seconds) of real samples: 424.0614375
Lengths (in seconds) of fake samples: 3624.6846875
Lengths (in seconds) of real samples: 350.6946875
Lengths (in seconds) of fake samples: 3809.648
Lengths (in seconds) of real samples: 458.1223125
Lengths (in seconds) of fake samples: 4087.7876875
Lengths (in seconds) of real samples: 439.1545625
Lengths (in seconds) of fake samples: 4109.019375
Converting into spectrogram
We have managed to concatenate the audios. Then we we can follow the same process as previous kaggle dataset to convert them into 30 secs segement and spectrogram
# this function similiar to previous splitting function, but using .flac files as input instead
def split_audio_flac(file_path, segment_length=30000, random_length = None):
"""
Split the audio file into segments of given length (in milliseconds).
Returns a list of audio segments.
"""
audio = AudioSegment.from_file(file_path, format="flac")
length_audio = len(audio)
segments = []
# Random Length: None or [lower, upper]
# Generating a random segement length from lower to upper range
if random_length is not None:
current_length = 0
while current_length < len(audio):
segment_length = np.random.randint(random_length[0],random_length[1],1)
if current_length + segment_length >= len(audio):
segment = audio[current_length:]
else:
segment = audio[current_length:current_length + segment_length]
current_length += segment_length
segments.append(segment)
# fix length: segment_length
else:
for i in range(0, length_audio, segment_length):
segment = audio[i:i + segment_length]
segments.append(segment)
return segments
Training Set
we will first process training dataset in original ASVspoof 2019 contest
fake_files = os.listdir('LA_concated/train/fake')
real_files = os.listdir('LA_concated/train/real')
covert real voice into 30 second segement and spectrogram
os.makedirs('real',exist_ok=True)
#remove old files if exists
remove_all_files('real')
for wav_file in real_files:
print('Processing: ', wav_file)
output_folder = 'real'
if wav_file[-5:] == '.flac':
segments = split_audio_flac('LA_concated/train/real/'+wav_file)
for i, segment in enumerate(segments):
samples = np.array(segment.get_array_of_samples())
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate, NFFT=1024, noverlap=512)
plt.axis('off')
plt.savefig(os.path.join('real', wav_file[:-5]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
fake voice
os.makedirs('fake',exist_ok=True)
# remove_all_files('fake')
for wav_file in fake_files[12:]:
print('Processing: ', wav_file)
if wav_file[-5:] == '.flac':
segments = split_audio_flac('LA_concated/train/fake/'+wav_file)
for i, segment in enumerate(segments):
samples = np.array(segment.get_array_of_samples())
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate, NFFT=1024, noverlap=512)
plt.axis('off')
plt.savefig(os.path.join('fake', wav_file[:-5]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
real_path = '/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/train/1'
fake_path = '/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/train/0'
real_spectro = os.listdir(real_path)
fake_spectro = os.listdir(fake_path)
print(f'There are {len(real_spectro)} real samples in training set, each contain 30 seconds of voices in spectrogram')
print(f'There are {len(fake_spectro)} fake samples in training set')
There are 303 real samples in training set, each contain 30 seconds of voices in spectrogram
There are 2615 fake samples in training set
Note: this is still an imbalanced dataset
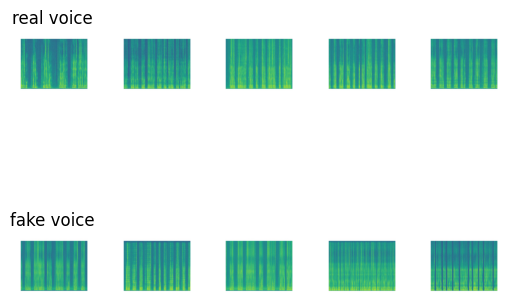
some samples
# Display random five real and fake voice spectrogram
count = 0
fig, axs = plt.subplots(2,5)
for i in np.random.choice(range(len(real_spectro)),5):
image_path = real_spectro[i]
image = mpimg.imread(os.path.join(real_path,image_path))
axs[0,count].imshow(image)
image_path = fake_spectro[i]
image = mpimg.imread(os.path.join(fake_path,image_path))
axs[1,count].imshow(image)
axs[0,count].axis('off')
axs[1,count].axis('off')
if count == 0:
axs[0,count].set_title('real voice')
axs[1,count].set_title('fake voice')
count += 1
Test and Validation Set
Similiarly, we also converted the test set into the spectrogram using the same process as train set
fake_files = os.listdir('LA_concated/test/fake')
real_files = os.listdir('LA_concated/test/real')
#converting real
output_folder = 'LA_Spectrogram/test/1'
os.makedirs(output_folder,exist_ok=True)
for wav_file in real_files:
print('Processing: ', wav_file)
if wav_file[-5:] == '.flac':
segments = split_audio_flac('LA_concated/test/real/'+wav_file)
for i, segment in enumerate(segments):
samples = np.array(segment.get_array_of_samples())
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate, NFFT=1024, noverlap=512)
plt.axis('off')
plt.savefig(os.path.join(output_folder, wav_file[:-5]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
#converting fake
output_folder = 'LA_Spectrogram/test/0'
os.makedirs(output_folder,exist_ok=True)
for wav_file in fake_files[11:]:
print('Processing: ', wav_file)
if wav_file[-5:] == '.flac':
segments = split_audio_flac('LA_concated/test/fake/'+wav_file)
for i, segment in enumerate(segments):
samples = np.array(segment.get_array_of_samples())
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate, NFFT=1024, noverlap=512)
plt.axis('off')
plt.savefig(os.path.join(output_folder, wav_file[:-5]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
validation set as well
fake_files = os.listdir(location + 'LA_concated/validation/fake')
real_files = os.listdir(location + 'LA_concated/validation/real')
#converting real
output_folder = 'LA_Spectrogram/validation/1'
os.makedirs(output_folder,exist_ok=True)
for wav_file in real_files:
print('Processing: ', wav_file)
if wav_file[-5:] == '.flac':
segments = split_audio_flac(location + 'LA_concated/validation/real/'+wav_file)
for i, segment in enumerate(segments):
samples = np.array(segment.get_array_of_samples())
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate, NFFT=1024, noverlap=512)
plt.axis('off')
plt.savefig(os.path.join(output_folder, wav_file[:-5]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
#converting fake
output_folder = 'LA_Spectrogram/validation/0'
os.makedirs(output_folder,exist_ok=True)
for wav_file in fake_files[7:]:
print('Processing: ', wav_file)
if wav_file[-5:] == '.flac':
segments = split_audio_flac(location + 'LA_concated/validation/fake/'+wav_file)
for i, segment in enumerate(segments):
samples = np.array(segment.get_array_of_samples())
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate, NFFT=1024, noverlap=512)
plt.axis('off')
plt.savefig(os.path.join(output_folder, wav_file[:-5]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
All samples are pre-splited which allows us to using this way to converting dataset, and the file structure is ready for torchvison to use
Unseen samples for model evaluation
We need to evaluate the model performance on unseen samples.
We would use another dataset which consists of original voice audios and fake audios obtained by imitation using Efficient Wavelet Masking (Rodríguez, 2019) to evaluate our final model.
This dataset was processed into spectrograms in the same way as previously. But we want to keep the length as its original length, which is not fixed 30 seconds, since this is more fit to the real world usage.
real_unseen = os.listdir('/content/drive/MyDrive/shared-project-folder/Fake_voice_recordings_Imitation/real')
fake_unseen = os.listdir('/content/drive/MyDrive/shared-project-folder/Fake_voice_recordings_Imitation/fake')
#remove old files
remove_all_files('/content/drive/MyDrive/shared-project-folder/unseen/test/real')
remove_all_files('/content/drive/MyDrive/shared-project-folder/unseen/test/fake')
for file_path in real_unseen:
if file_path[-4:] == '.wav':
segments = split_audio('/content/drive/MyDrive/shared-project-folder/Fake_voice_recordings_Imitation/real/'+file_path)
# the audios have various lengths and are shorter than 30 seconds,
# so split_audio just keeps the whole sequence without creating 30-second intervals
for i, segment in enumerate(segments):
segment = segment.set_channels(1)
samples = np.array(segment.get_array_of_samples())
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate)
im.axes.get_xaxis().set_visible(False)
im.axes.get_yaxis().set_visible(False)
plt.axis('off')
output_folder = os.path.join('/content/drive/MyDrive/shared-project-folder/unseen/', 'test', '1')
os.makedirs(os.path.join(output_folder),exist_ok=True)
plt.savefig(os.path.join(output_folder, file_path[:-4]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
for file_path in fake_unseen:
if file_path[-4:] == '.wav':
segments = split_audio('/content/drive/MyDrive/shared-project-folder/Fake_voice_recordings_Imitation/fake/'+file_path)
for i, segment in enumerate(segments):
segment = segment.set_channels(1)
samples = np.array(segment.get_array_of_samples())
specgram, freqs, times, im = plt.specgram(samples, Fs=segment.frame_rate)
im.axes.get_xaxis().set_visible(False)
im.axes.get_yaxis().set_visible(False)
#change y range
plt.axis('off')
output_folder = os.path.join('/content/drive/MyDrive/shared-project-folder/unseen/', 'test', '0')
os.makedirs(os.path.join(output_folder),exist_ok=True)
plt.savefig(os.path.join(output_folder, file_path[:-4]+'_'+str(i+1)+'.jpg'), format="jpg")
plt.close("all")
Lets see some samples in unseen samples
real_path = '/content/drive/MyDrive/shared-project-folder/unseen/test/1'
fake_path = '/content/drive/MyDrive/shared-project-folder/unseen/test/0'
real_spectro = os.listdir(real_path)
fake_spectro = os.listdir(fake_path)
count = 0
fig, axs = plt.subplots(2,5)
for i in np.random.choice(range(len(real_spectro)),5):
image_path = real_spectro[i]
image = mpimg.imread(os.path.join(real_path,image_path))
axs[0,count].imshow(image)
image_path = fake_spectro[i]
image = mpimg.imread(os.path.join(fake_path,image_path))
axs[1,count].imshow(image)
axs[0,count].axis('off')
axs[1,count].axis('off')
if count == 0:
axs[0,count].set_title('real voice')
axs[1,count].set_title('fake voice')
count += 1
Model training and eveluation
We first defined some helper functions which created dataloaders to access training data and validation data, and computed the accuracy and the F1 score of the model.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.data import random_split
def spliting_data(path, batch_size, split = 0.2):
# if the google drive is mounted, we can store the dataset
# into google drive for future usage (make sure creating a shortcut of 'shared
# project folder'in 'My Drive')
if os.path.exists('drive'):
location = '/content/drive/MyDrive/shared-project-folder/'
else:
# if not, stored it in runtime (required downloading processing data everytime)
location = ''
#kaggle dataset
data_dir = location + path
#resize the spectrogram
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
print('Reading Data')
#using both dataset
if path == 'both':
dataset1 = datasets.ImageFolder('/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/train', transform=transform)
val_dataset1 = datasets.ImageFolder('/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/validation', transform=transform)
#kaggle dataset does not pre-split
dataset2 = datasets.ImageFolder('/content/drive/MyDrive/shared-project-folder/kaggle/train', transform=transform)
train_size = int((1-split) * len(dataset2))
val_size = len(dataset2) - train_size
dataset2, val_dataset2 = random_split(dataset2, [train_size, val_size])
train_dataset = torch.utils.data.ConcatDataset([dataset1, dataset2])
val_dataset = torch.utils.data.ConcatDataset([val_dataset1, val_dataset2])
# using single one dataset
else:
if path == 'kaggle':
#using kaggle
dataset = datasets.ImageFolder('/content/drive/MyDrive/shared-project-folder/kaggle/train', transform=transform)
train_size = int((1-split) * len(dataset))
al_size = len(dataset2) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
else:
#using asvsproof
train_dataset = datasets.ImageFolder('/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/train', transform=transform)
val_dataset = datasets.ImageFolder('/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/validation', transform=transform)
print(f'Training Sample: {len(train_dataset)}')
print(f'Validation Sample: {len(val_dataset)}')
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
return train_loader, val_loader
# evalation the performance
def evaluate(model, test_loader):
model.eval()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
test_loss = 0
test_accuracy = 0
test_f1 = 0
criterion = nn.CrossEntropyLoss()
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
test_loss += criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
labels = labels.cpu()
predicted = predicted.cpu()
test_accuracy += accuracy_score(labels, predicted)
test_f1 += f1_score(labels, predicted)
return test_loss.detach().cpu() / len(test_loader), test_f1 / len(test_loader),test_accuracy / len(test_loader)
Also, another helper function for training
from sklearn.metrics import f1_score
from sklearn.metrics import accuracy_score
def train(model, dataset_path, epoches = 30, learning_rate = 0.0001,
batch_size = 32, check_point = True, random_state = 42, plot = True):
torch.manual_seed(random_state)
model = model
train_loader, val_loader = spliting_data(dataset_path,batch_size)
# Assuming you have your train_loader set up as before
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Move the model to the GPU if available
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
num_epochs = epoches
training_loss = []
training_accuracy = []
training_f1 = []
validation_loss = []
validation_accuracy = []
validation_f1 = []
for epoch in tqdm(range(num_epochs), leave = False, desc = f'Epoch'):
# Set the model to training mode
model.train()
running_loss = 0.0
correct = 0
total = 0
f1 = 0
accuracy = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# Calculate accuracy
_, predicted = torch.max(outputs.data, 1)
labels = labels.cpu()
predicted = predicted.cpu()
accuracy += accuracy_score(labels, predicted)
f1 += f1_score(labels, predicted)
epoch_loss = running_loss / len(train_loader)
epoch_f1 = f1 / len(train_loader)
epoch_accuracy = accuracy/ len(train_loader)
#print, eval, and store every 2:
if epoch % 2 == 0:
training_loss.append(epoch_loss)
training_accuracy.append(epoch_accuracy)
training_f1.append(epoch_f1)
epoch_val_loss, epoch_val_f1, epoch_val_accuracy = evaluate(model, val_loader)
validation_loss.append(epoch_val_loss)
validation_accuracy.append(epoch_val_accuracy)
validation_f1.append(epoch_val_f1)
#save checkpoint
if check_point:
checkpoint = {'epoch': epoch,'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),'loss': loss}
out_path = dataset_path.split('/')[0]+f'/{model.name}/lr_{learning_rate}_batch_{batch_size}_new'
os.makedirs(location + out_path,exist_ok=True)
checkpoint_filename = f'checkpoint_epoch{epoch+1}.pth'
torch.save(checkpoint, os.path.join(location + out_path,checkpoint_filename))
print(f'''
Epoch {epoch+1}/{num_epochs}
Train Loss: {epoch_loss:.4f}, Train Accuracy: {epoch_accuracy:.2f}, Train F1: {epoch_f1:.2f}
Val Loss: {epoch_val_loss:.4f}, Val Accuracy: {epoch_val_accuracy:.2f}, Val F1: {epoch_val_f1:.2f}
''')
if plot:
# Plot the training loss and accuracy curves
plt.figure(figsize=(18, 6))
plt.subplot(1, 3, 1)
plt.plot(range(1, num_epochs + 1,2), training_loss, label='Training Loss')
plt.plot(range(1, num_epochs + 1,2), validation_loss, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.legend()
plt.subplot(1, 3, 2)
plt.plot(range(1, num_epochs + 1,2), training_accuracy, label='Training Accuracy')
plt.plot(range(1, num_epochs + 1,2), validation_accuracy, label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.title('Training Accuracy Curve')
plt.legend()
plt.subplot(1, 3, 3)
plt.plot(range(1, num_epochs + 1,2), training_f1, label='Training Accuracy')
plt.plot(range(1, num_epochs + 1,2), validation_f1, label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('F1 Score')
plt.title('F1 Score Curve')
plt.legend()
plt.show()
return model
Baseline Model
We first trained a CNN without transferred learning from ResNet as the baseline model. This CNN simply had 2 convolution layers each followed by max-pooling, and 3 fully-connected layers. Activation function between the 3 fully-connected layers was ReLu.
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.name = "SimpleCNN"
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 53 * 53, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 53 * 53)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Training
model = SimpleCNN()
# 'both' will combine two dataset,
#' kaggle/train' will only used kaggle dataset
# 'LA_Spectrogram/train' will used ASVsproof dataset
train(model, 'both',batch_size=64,learning_rate=0.001)
Reading Data
Training Sample: 2986
Validation Sample: 747
Epoch: 3%|▎ | 1/30 [05:24<2:36:47, 324.39s/it]
Epoch 1/30
Train Loss: 0.3613, Train Accuracy: 0.89, Train F1: 0.00
Val Loss: 0.3500, Val Accuracy: 0.89, Val F1: 0.00
Epoch: 10%|█ | 3/30 [06:35<45:24, 100.90s/it]
Epoch 3/30
Train Loss: 0.3125, Train Accuracy: 0.90, Train F1: 0.06
Val Loss: 0.3126, Val Accuracy: 0.91, Val F1: 0.27
Epoch: 17%|█▋ | 5/30 [07:48<25:43, 61.74s/it]
Epoch 5/30
Train Loss: 0.2594, Train Accuracy: 0.91, Train F1: 0.26
Val Loss: 0.2729, Val Accuracy: 0.90, Val F1: 0.27
Epoch: 23%|██▎ | 7/30 [08:56<17:52, 46.63s/it]
Epoch 7/30
Train Loss: 0.1809, Train Accuracy: 0.93, Train F1: 0.55
Val Loss: 0.2037, Val Accuracy: 0.92, Val F1: 0.45
Epoch: 30%|███ | 9/30 [10:04<14:10, 40.49s/it]
Epoch 9/30
Train Loss: 0.0904, Train Accuracy: 0.97, Train F1: 0.80
Val Loss: 0.1039, Val Accuracy: 0.96, Val F1: 0.81
Epoch: 37%|███▋ | 11/30 [11:14<12:00, 37.92s/it]
Epoch 11/30
Train Loss: 0.0697, Train Accuracy: 0.97, Train F1: 0.86
Val Loss: 0.0878, Val Accuracy: 0.96, Val F1: 0.82
Epoch: 43%|████▎ | 13/30 [12:23<10:18, 36.41s/it]
Epoch 13/30
Train Loss: 0.0398, Train Accuracy: 0.99, Train F1: 0.92
Val Loss: 0.0806, Val Accuracy: 0.96, Val F1: 0.83
Epoch: 50%|█████ | 15/30 [13:32<08:58, 35.90s/it]
Epoch 15/30
Train Loss: 0.0238, Train Accuracy: 0.99, Train F1: 0.97
Val Loss: 0.0811, Val Accuracy: 0.97, Val F1: 0.83
Epoch: 57%|█████▋ | 17/30 [14:41<07:41, 35.52s/it]
Epoch 17/30
Train Loss: 0.0092, Train Accuracy: 1.00, Train F1: 0.99
Val Loss: 0.0564, Val Accuracy: 0.98, Val F1: 0.89
Epoch: 63%|██████▎ | 19/30 [15:49<06:26, 35.15s/it]
Epoch 19/30
Train Loss: 0.0018, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0630, Val Accuracy: 0.98, Val F1: 0.89
Epoch: 70%|███████ | 21/30 [17:00<05:21, 35.68s/it]
Epoch 21/30
Train Loss: 0.0007, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0677, Val Accuracy: 0.98, Val F1: 0.90
Epoch: 77%|███████▋ | 23/30 [18:09<04:06, 35.25s/it]
Epoch 23/30
Train Loss: 0.0004, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0718, Val Accuracy: 0.98, Val F1: 0.91
Epoch: 83%|████████▎ | 25/30 [19:17<02:54, 34.99s/it]
Epoch 25/30
Train Loss: 0.0003, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0697, Val Accuracy: 0.98, Val F1: 0.89
Epoch: 90%|█████████ | 27/30 [20:30<01:47, 35.86s/it]
Epoch 27/30
Train Loss: 0.0002, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0737, Val Accuracy: 0.98, Val F1: 0.90
Epoch: 97%|█████████▋| 29/30 [21:41<00:35, 35.89s/it]
Epoch 29/30
Train Loss: 0.0002, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0744, Val Accuracy: 0.98, Val F1: 0.89
SimpleCNN(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=44944, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=2, bias=True)
)
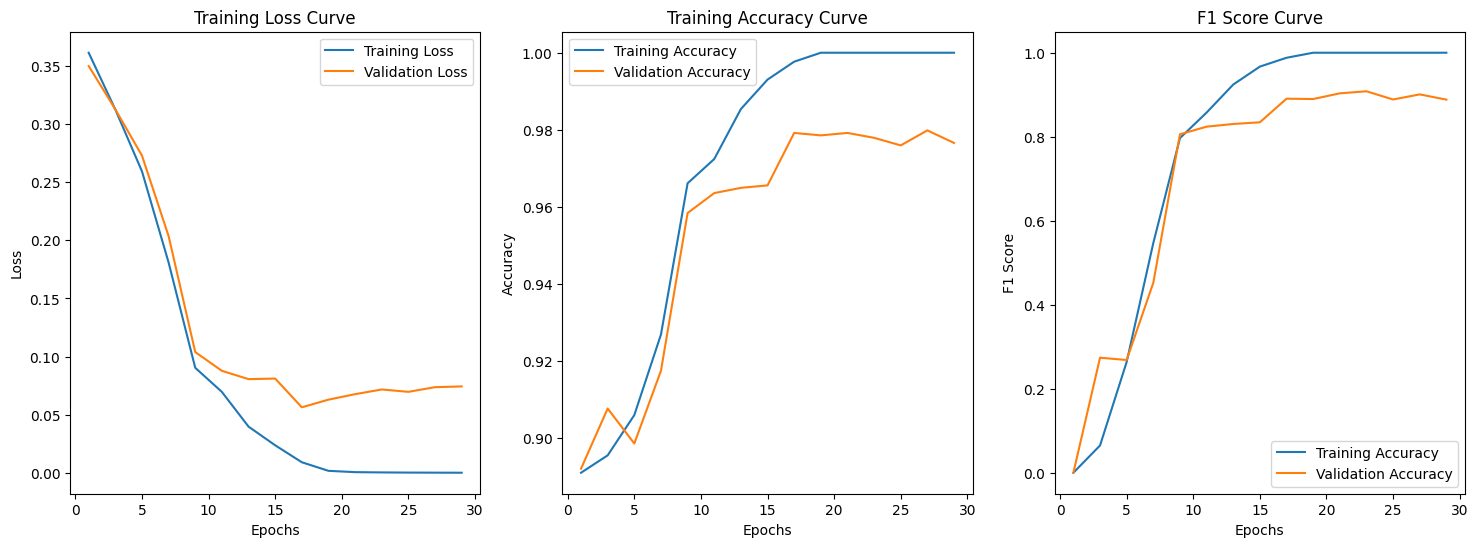
The highest validation F1 we got was 0.91 and the corresponding accuracy was 0.98. A validation F1 of 0.91 is very good (Buhl, 2023), but by tuning hyperparameters based on validation F1, the model might have overfit on the validation data, so we should check the performance on the test data.
Evaluation
We loaded the trained baseline model.
model = SimpleCNN()
#load the checkpoint with lowest F1
path = location + '/both/SimpleCNN/lr_0.001_batch_64/checkpoint_epoch23.pth'
checkpoint = torch.load(path)
model_state_dict = checkpoint['model_state_dict']
model.load_state_dict(model_state_dict)
<All keys matched successfully>
Then we evaluated the model’s performance on the test data. Note that the test data consisted of test samples from both “Deep-Voice” on Kaggle and ASVspoof2019 LA.
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
test_dataset1 = datasets.ImageFolder((location + 'kaggle/test'), transform=transform)
test_dataset2 = datasets.ImageFolder((location + 'LA_Spectrogram/test'), transform=transform)
test_dataset = torch.utils.data.ConcatDataset([test_dataset1, test_dataset2])
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)
loss, f1, accuracy = evaluate(model, test_loader)
print(f'The F1-Score for Testing Dataset is {f1}')
print(f'The accuracy for Testing Dataset is {accuracy}')
The F1-Score for Testing Dataset is 0.7845597579699278
The accuracy for Testing Dataset is 0.9271012931034484
Although the test accuracy of baseline model was high (0.927), the F1 score for the testing dataset was relatively low (0.785). This means that the model didn’t achieve an as satisfying balance between precision and recall as it did on the validation set. Since our training,validation and test data all had more fake samples than real samples, the baseline model might be classifying samples as fake without learning sufficient features.
Transfer Learning: Pre-train Res-Net
Our next step was to build a model that utilized transferred learning from ResNet18. The architecture was composed of 1 convolution layer followed by the pretrained ResNet18, and 2 fully-connected layers in the end. We did not freeze the parameters from ResNet18. In other words, they were subject to update by backpropagation. Our justification was that ResNet18 was pretrained on ImageNet which did not contain any spectrograms or other signal visualizations.
import torch
import torchvision.models as models
import torch.nn as nn
class PreTrainedResNet18(nn.Module):
def __init__(self):
super().__init__()
self.name = 'PreRes'
self.conv1 = nn.Conv2d(3, 3, kernel_size=7, stride=2, padding=3, bias=False)
self.resnet = models.resnet18(pretrained=True)
self.fc1 = nn.Linear(1000, 100)
self.fc2 = nn.Linear(100, 2)
self.activation = nn.ReLU()
self.dropout = nn.Dropout(p=0.1)
# Copy the pre-trained model weights except for the first convolution layer
state_dict = self.resnet.state_dict()
for key in list(state_dict.keys()):
if not key.startswith('conv1'):
self.state_dict()[key] = state_dict[key]
def forward(self, x):
x = self.conv1(x)
x = self.resnet(x)
x = self.activation(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
Model Training and Fine-tuning
# training
model_resnet = PreTrainedResNet18()
model_resnet = train(model_resnet, 'both',batch_size=256,learning_rate=0.0001)
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /root/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth
100%|██████████| 44.7M/44.7M [00:00<00:00, 120MB/s]
Reading Data
Training Sample: 2986
Validation Sample: 747
Epoch: 3%|▎ | 1/30 [01:09<33:42, 69.73s/it]
Epoch 1/30
Train Loss: 0.3109, Train Accuracy: 0.86, Train F1: 0.31
Val Loss: 0.3418, Val Accuracy: 0.89, Val F1: 0.00
Epoch: 10%|█ | 3/30 [02:22<20:03, 44.57s/it]
Epoch 3/30
Train Loss: 0.0240, Train Accuracy: 0.99, Train F1: 0.97
Val Loss: 0.2347, Val Accuracy: 0.91, Val F1: 0.35
Epoch: 17%|█▋ | 5/30 [03:34<16:26, 39.48s/it]
Epoch 5/30
Train Loss: 0.0028, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0516, Val Accuracy: 0.98, Val F1: 0.91
Epoch: 23%|██▎ | 7/30 [04:44<14:23, 37.53s/it]
Epoch 7/30
Train Loss: 0.0004, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0246, Val Accuracy: 0.99, Val F1: 0.96
Epoch: 30%|███ | 9/30 [05:57<13:00, 37.17s/it]
Epoch 9/30
Train Loss: 0.0001, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0205, Val Accuracy: 1.00, Val F1: 0.98
Epoch: 37%|███▋ | 11/30 [07:08<11:36, 36.66s/it]
Epoch 11/30
Train Loss: 0.0001, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0209, Val Accuracy: 0.99, Val F1: 0.97
Epoch: 43%|████▎ | 13/30 [08:20<10:23, 36.66s/it]
Epoch 13/30
Train Loss: 0.0001, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0204, Val Accuracy: 0.99, Val F1: 0.96
Epoch: 50%|█████ | 15/30 [09:32<09:07, 36.53s/it]
Epoch 15/30
Train Loss: 0.0001, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0209, Val Accuracy: 0.99, Val F1: 0.97
Epoch: 57%|█████▋ | 17/30 [10:43<07:52, 36.37s/it]
Epoch 17/30
Train Loss: 0.0001, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0198, Val Accuracy: 0.99, Val F1: 0.97
Epoch: 63%|██████▎ | 19/30 [11:59<06:58, 38.02s/it]
Epoch 19/30
Train Loss: 0.0001, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0207, Val Accuracy: 0.99, Val F1: 0.97
Epoch: 70%|███████ | 21/30 [13:10<05:33, 37.06s/it]
Epoch 21/30
Train Loss: 0.0000, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0204, Val Accuracy: 0.99, Val F1: 0.97
Epoch: 77%|███████▋ | 23/30 [14:21<04:16, 36.60s/it]
Epoch 23/30
Train Loss: 0.0000, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0210, Val Accuracy: 0.99, Val F1: 0.96
Epoch: 83%|████████▎ | 25/30 [15:33<03:02, 36.54s/it]
Epoch 25/30
Train Loss: 0.0000, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0209, Val Accuracy: 0.99, Val F1: 0.97
Epoch: 90%|█████████ | 27/30 [16:46<01:49, 36.60s/it]
Epoch 27/30
Train Loss: 0.0000, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0216, Val Accuracy: 0.99, Val F1: 0.97
Epoch: 97%|█████████▋| 29/30 [17:56<00:36, 36.26s/it]
Epoch 29/30
Train Loss: 0.0000, Train Accuracy: 1.00, Train F1: 1.00
Val Loss: 0.0222, Val Accuracy: 0.99, Val F1: 0.97
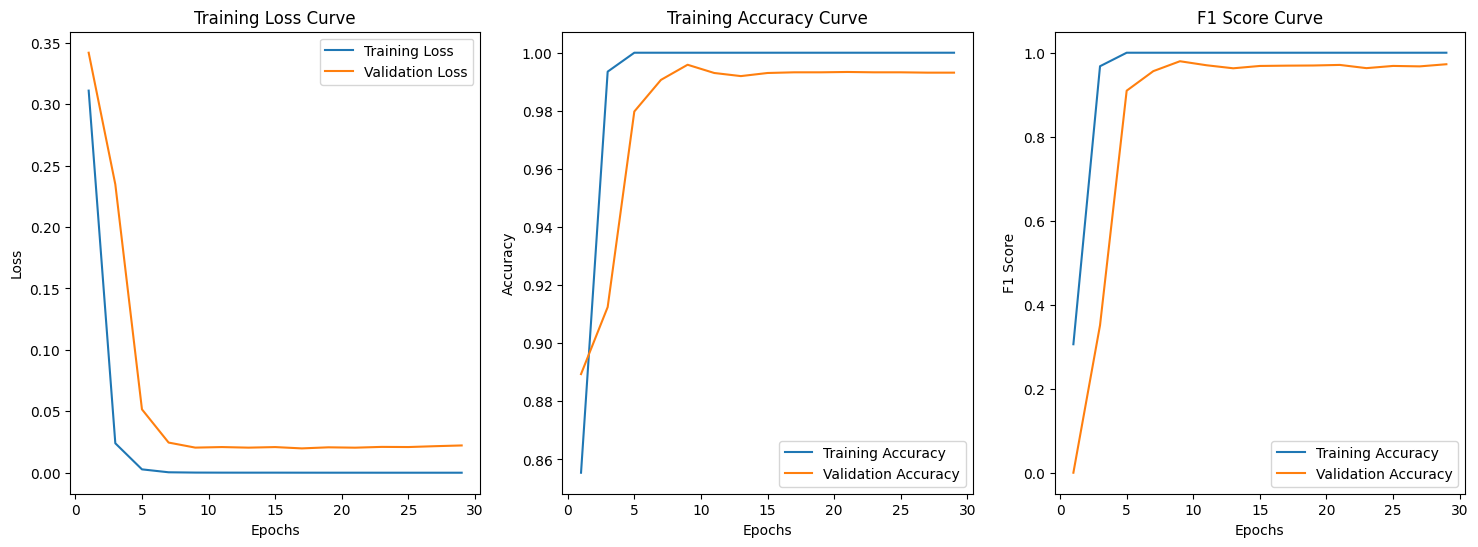
The highest validation F1 was 0.98, and the validation accuracy was approximately 1. This was an improvement of the baseline model. Comparing the training curves, we also saw that in terms of epochs, the ResNet18 model was converging faster and smoother. Then we checked its performance on the test data.
# load the best model
model_resnet = PreTrainedResNet18()
path = location+'both/PreRes/lr_0.0001_batch_256/checkpoint_epoch9.pth'
checkpoint = torch.load(path, map_location=torch.device('cpu'))
model_state_dict = checkpoint['model_state_dict']
model_resnet.load_state_dict(model_state_dict)
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /root/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth
100%|██████████| 44.7M/44.7M [00:00<00:00, 77.1MB/s]
<All keys matched successfully>
# evaluate by the test dataset
loss, f1, accuracy = evaluate(model_resnet, test_loader)
print(f'The F1-Score for Testing Dataset is {f1}')
print(f'The accuracy for Testing Dataset is {accuracy}')
The F1-Score for Testing Dataset is 0.8942586360721817
The accuracy for Testing Dataset is 0.9690193965517241
While the test accuracies were close (0.969 v.s. 0.927), test F1 of ResNet18 model was quite higher (0.894 v.s. 0.785), so utilizing ResNet18 helped us achieve better balance between precision and recall. Our final model would be the ResNet18 model.
Unseen samples
At the end of model training, we wish to test our best model with the unseen samples we prepared before. There are 50 fake samples, and 50 real samples.
test_dataset = datasets.ImageFolder(('/content/drive/MyDrive/shared-project-folder/unseen/test'), transform=transform)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)
loss, f1, accuracy = evaluate(model_resnet, test_loader)
print(f'The F1-Score for Testing Dataset is {f1}')
print(f'The accuracy for Testing Dataset is {accuracy}')
The F1-Score for Testing Dataset is 0.8282732447817838
The accuracy for Testing Dataset is 0.8402777777777778
At this point we tested our final ResNet18 model on new spectrograms. It was expectable that the F1 score and the accuracy decrease as the audios from which the new spectrograms were generated in one unique method, which was likely not included in ASVspoof2019 LA (the generation methods were labeled anonymously). The F1 score didn’t drop too much (0.828 v.s. 0.894) and was still satisfactory (Buhl, 2023).
We think the model exhibits fairly good performance on unseen samples from a completely new dataset. Although it may be lower than the performance on the previous testing dataset, it’s noteworthy that the AI-generated voices originate from different models, use distinct methods, feature various speakers, and differ in audio length compared to our training data. Therefore, we believe our model’s performance remains robust.
Here is an example of unseen samples
#read one image and transform
from PIL import Image
fig, ax = plt.subplots(1,2,figsize=(10,5))
image = Image.open('/content/drive/MyDrive/shared-project-folder/unseen/test/0/fake5_10_1.jpg')
ax[0].imshow(image)
test_image, label = transform(image), 0
test_image = test_image.unsqueeze(0)
_,predicted = torch.max(model_resnet(test_image),1)
ax[0].set_title('Predicted: ' + ['Fake','Real'][predicted.item()]+' Label: '+['Fake','Real'][label])
image = Image.open('/content/drive/MyDrive/shared-project-folder/unseen/test/1/speaker1_6_1.jpg')
ax[1].imshow(image)
test_image, label = transform(image), 1
test_image = test_image.unsqueeze(0)
_,predicted = torch.max(model_resnet(test_image),1)
ax[1].set_title('Predicted: ' + ['Fake','Real'][predicted.item()]+' Label: '+['Fake','Real'][label])
plt.show()
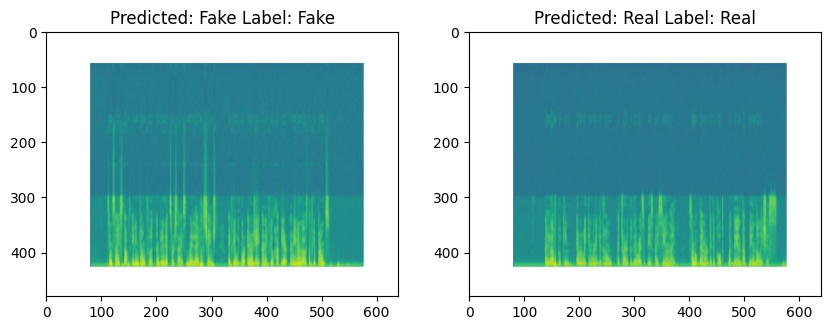
The printed 2 spectrograms came from 2 audios which we were unable to classify by hearing them on ourselves, yet the ResNet18 model was able to classify them correctly.
Qualitative explanation
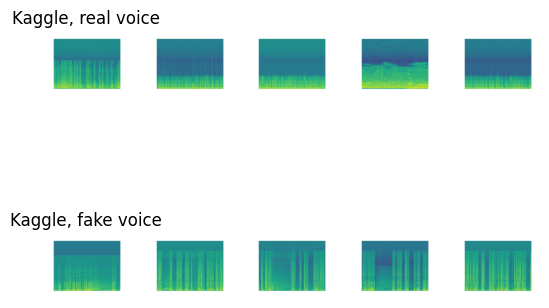
The key reason that even the baseline CNN model achieved a high validation accuracy of 0.98 lay among the spectrograms. We re-visited some spectrograms in the training set from “Deep-Voice” on Kaggle and ASVspoof2019 LA.
real_spectro = os.listdir('/content/drive/MyDrive/shared-project-folder/kaggle/real')
fake_spectro = os.listdir('/content/drive/MyDrive/shared-project-folder/kaggle/fake')
# Display random five real and fake voice spectrogram
np.random.seed(1)
count = 0
fig, axs = plt.subplots(2,5)
for i in np.random.choice(range(len(real_spectro)),5):
image_path = real_spectro[i]
image = mpimg.imread(os.path.join('/content/drive/MyDrive/shared-project-folder/kaggle/real',image_path))
axs[0,count].imshow(image)
image_path = fake_spectro[i]
image = mpimg.imread(os.path.join('/content/drive/MyDrive/shared-project-folder/kaggle/fake',image_path))
axs[1,count].imshow(image)
axs[0,count].axis('off')
axs[1,count].axis('off')
if count == 0:
axs[0,count].set_title('Kaggle, real voice')
axs[1,count].set_title('Kaggle, fake voice')
count += 1
real_spectro = os.listdir('/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/train/1')
fake_spectro = os.listdir('/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/train/0')
np.random.seed(1)
count = 0
fig, axs = plt.subplots(2,5)
for i in np.random.choice(range(len(real_spectro)),5):
image_path = real_spectro[i]
image = mpimg.imread(os.path.join('/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/train/1',image_path))
axs[0,count].imshow(image)
image_path = fake_spectro[i]
image = mpimg.imread(os.path.join('/content/drive/MyDrive/shared-project-folder/LA_Spectrogram/train/0',image_path))
axs[1,count].imshow(image)
axs[0,count].axis('off')
axs[1,count].axis('off')
if count == 0:
axs[0,count].set_title('ASVspoof, real voice')
axs[1,count].set_title('ASVspoof, fake voice')
count += 1
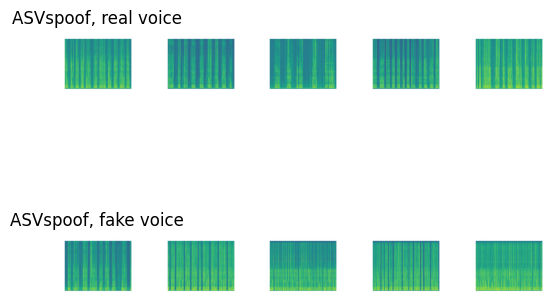
The spectrograms of the fake audios had some obvious visual differences from those of the real audios, including:
- certain frequencies being intensified/diminished
- different distances between vertical stripes, i.e. different lengths of silent intervals
These differences could be captured by CNN, and even more easily by ResNet which incorporated skip connections. However, when we humans listened to the audios, we could not hear the spectrograms.
Discussion
In our project, we’ve encountered several challenges related to datasets.
Initially, we thought finding the desired datasets would be straightforward.
However, we later found that the number of available datasets was less than expected. This is partly because some datasets only feature non-human voice audio. And some datasets have imbalance between real and fake audio samples. Certain datasets provide only fake audio or, only real audio.
Another challenge is the length of the audio files; most are under 10 seconds, which means we need to preprocess them to make them suitable for training.
Lastly, limiting our search to only English audio reduces the scope of our dataset options. But the question is: could we use non-English audio data for our task? It is a good question that we need to explore.
The important lesson we have learned is that we should be daring when we are facing unfamiliar tasks.
- When we came up with the idea to make a fake voice detector, we were concerned with the fact that we haven’t worked on audios during the course.
- Using spectrograms, which are images, as the input was a doubtful method because we suspected that spectrograms might not contain enough features of the audios to begin with.
- The ResNet18 model turned out to perform well.
It is worth noting that our final model may be vulnerable to adversarial attacks. For instance, it is possible to train a “modifier” which will erase the extra frequencies present in the spectrogram of fake audios, as illustrated in section ‘Unseen Samples’, in order to confuse our model to misclassify fake audios as real.
References
Jordan J. Bird, Ahmad Lotfi. REAL-TIME DETECTION OF AI-GENERATED SPEECH FOR DEEPFAKE VOICE CONVERSION,24 Aug 2023. https://arxiv.org/pdf/2308.12734.pdf
Yamagishi, Junichi; Todisco, Massimiliano; Sahidullah, Md; Delgado, Héctor; Wang, Xin; Evans, Nicolas; Kinnunen, Tomi; Lee, Kong Aik; Vestman, Ville; Nautsch, Andreas. (2019). ASVspoof 2019: The 3rd Automatic Speaker Verification Spoofing and Countermeasures Challenge database, [sound]. University of Edinburgh. The Centre for Speech Technology Research (CSTR). https://doi.org/10.7488/ds/2555.
Rodríguez, Yohanna; Ballesteros L, Dora Maria; Renza, Diego (2019), “Fake voice recordings (Imitation)”, Mendeley Data, V1, doi: 10.17632/ytkv9w92t6.1
Nikolaj Buhl. F1 Score in Machine Learning. Encord, 18 July 2023. https://encord.com/blog/f1-score-in-machine-learning/
Joe (Jiazhou) Liang
Data Scientist | Master Student @ University of Toronto
My research interests temporal clustering algorithms and its applications to solve real world problems.